Les 3 étapes de l'IA

Des méthodes d'IA différentes au cours du temps:
- code classique (
if → then → else) - système expert utilisant des règles créées à la main
- algorithmes statistiques apprenant les règles (machine learning)
Source: State-of-the-Art Mobile Intelligence (research paper)
Les systèmes experts
Le savoir est renseigné par des experts.


L'IA, c'est du Machine learning
Le savoir est extrait des données.

C'est auss le mariage de l'expérimentation et des statistiques:
c'est de la cuisine avec des algorithmes
Source: xkcd
Principes du machine learning
| Modèle | fait la prédiction régression linéaire, réseau de neurones, ... |
| Optimiseur | modifie le modèle pour réduire son erreur descente de gradient, algorithmes génétiques |
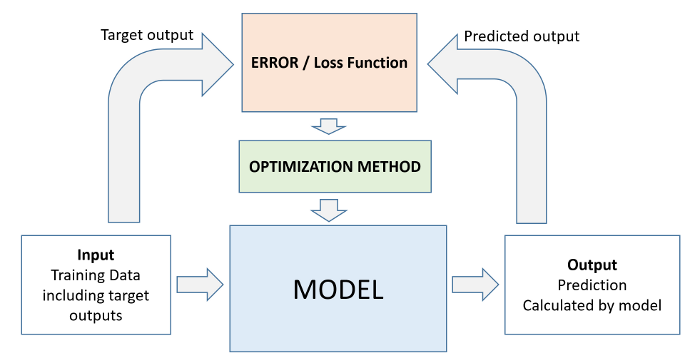
Source: From Linear Regression to Deep Learning in 5 Minutes
La programmation différentielle
Apprentissage = optimisation de fonctions différentiables
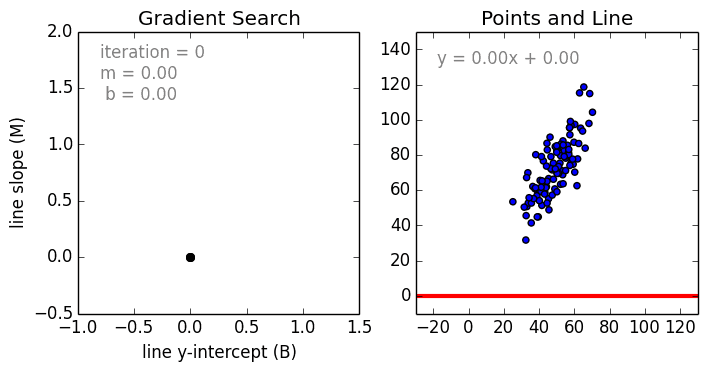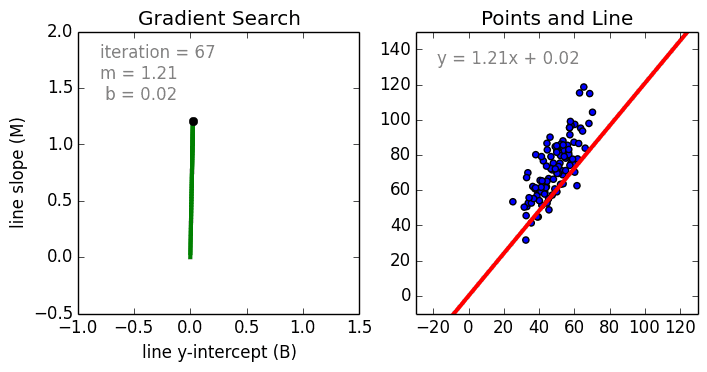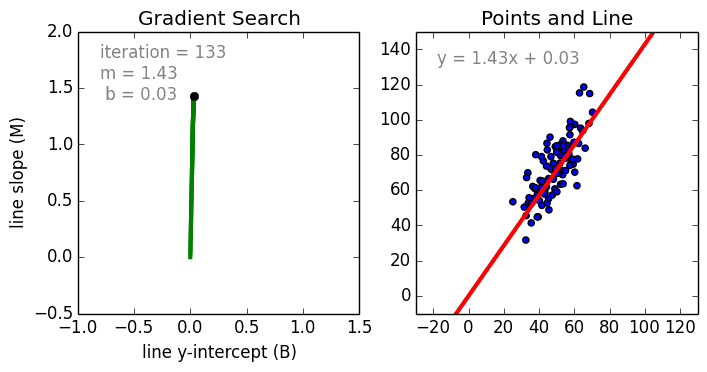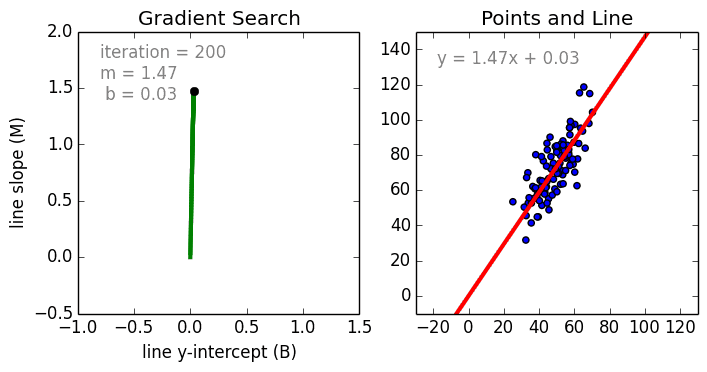
Une fonction différentiable permet de calculer le gradient de l'erreur.
A chaque itération, le gradient dit comment modifier les paramètres pour réduire l'erreur.
Source: Linear Regression by using Gradient Descent Algorithm: Your first step towards Machine Learning (medium)
La révolution du deep learning
La composition de modèles simples (neurones)
crée un modèle complexe.

Source: News Feature: What are the limits of deep learning? (PNAAS)
Le deep learning facilite la conception de modèle
👍 Plus besoin de créer des variables
👎 Nécessite beaucoup de données 💾 et de calculs 🥵

Source: Blue Hexagon
Quelles données pour évaluer ?

Une IA arrive détecte l'orientation sexuelle
à partir de la forme du visage !
Vraiment ? 🤔
Source: Do algorithms reveal sexual orientation or just expose our stereotypes?
Quelles données pour évaluer ?
L'IA utilise: barbe 🧔, lunettes 👓, maquillage 💄




L'IA reproduit les stéréotypes qu'elle trouve dans les données 🤦
Source: Do algorithms reveal sexual orientation or just expose our stereotypes?
Quelles données pour évaluer ?
Train-test split:
Séparer les données d'apprentissage
& les données d'évaluation

⚠️ la performance mesurée sur le train est toujours surestimée !
Source: Elite data science
L'Overfitting: l'erreur de débutant
Modèle qui "colle" aux données d'entraînement
sans retenir le savoir sous-jacent (bachottage)


Cela fait croire qu'un modèle est performant (en laboratoire),
alors qu'il est médiocre (en conditions réelles).
Source: Quora
Diagnostic du Covid-19
Test PCR du frottis nasopharyngé

| Faux positifs | 1 % |
| Faux négatifs | entre 15 et 45 % 😱 |
| Prévalence | entre 1 et 5 % en Ile-de-France |
Agile: fail fast, learn quick
Expérimentation: il faut payer pour voir 🃏

Source: CRISP-DM (Wikipedia)
Qualifier une idée de projet
Demander son avis à un expert:

Source: xkcd
Les données avant les algorithmes
L'IA, c'est des vieux algorithmes
appliqués à des données récentes.
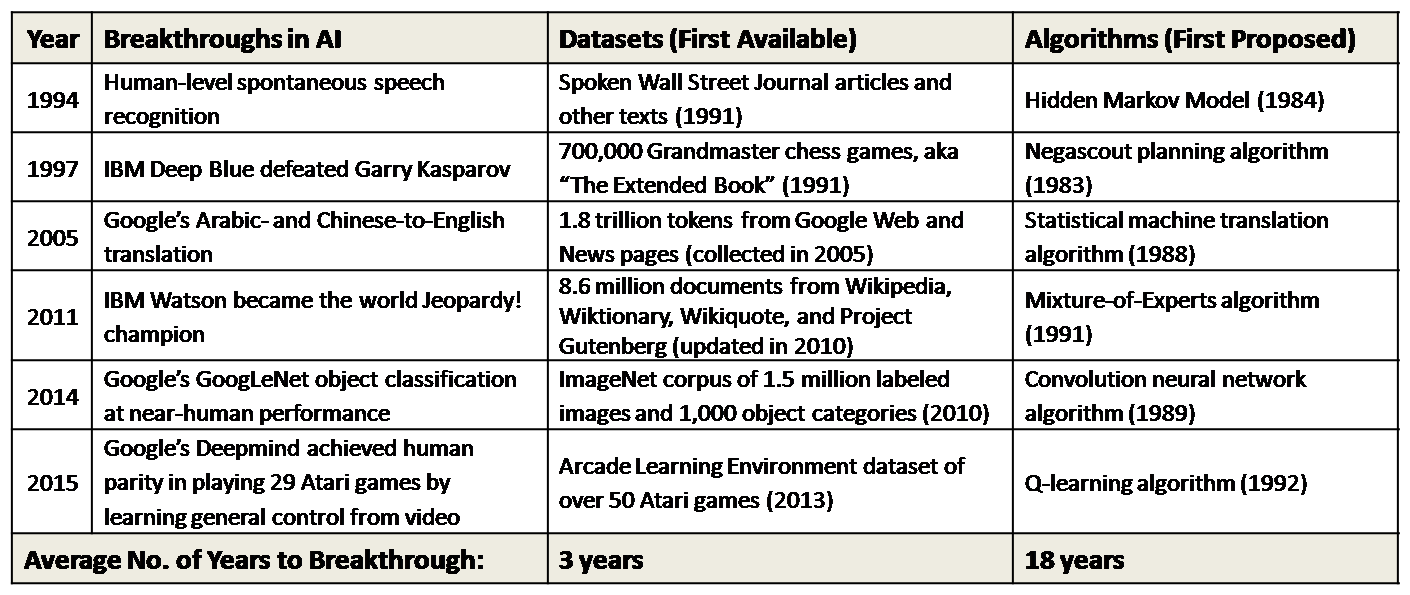
C'est la collecte de donnée qui permet les percées en IA.
Source: Datasets Over Algorithms (kdnuggets)
La connaissance des algorithmes ne se suffit pas à elle-même
Un bon data scientist doit être full-stack developer,
ou être intégré à une équipe plus large.
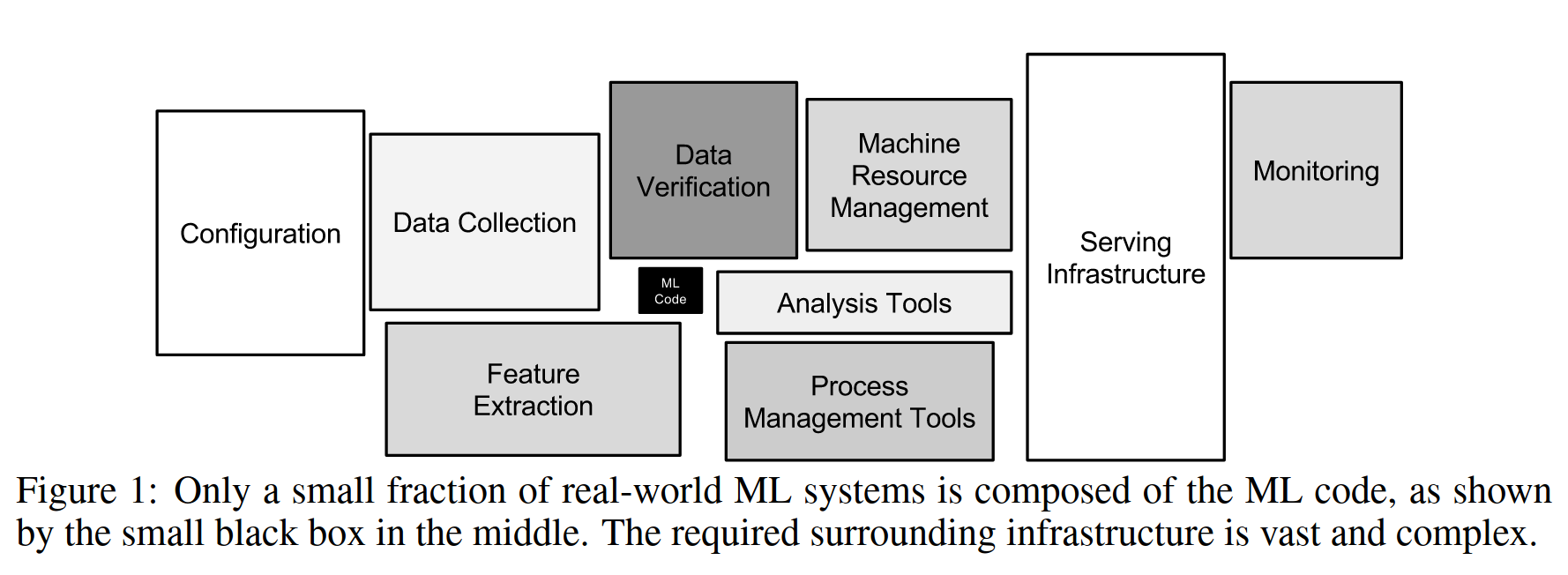
Faire du machine learning en laboratoire c'est facile,
mais savoir livrer une solution fonctionnelle est difficile.
Source Machine Learning: The High-Interest Credit Card of Technical Debt